Scripps team: Benjamin M. Good, Ginger Tsueng, Andrew I Su
Playmatics Team: Sarah Santini, Margaret Wallace, Nicholas Fortugno, John Szeder, Patrick Mooney,
With helpful ideas from: Jerome Waldispuhl, Melanie Stegman
Abstract
Games with a purpose and other kinds of citizen science initiatives demonstrate great potential for advancing biomedical science and improving STEM education. Articles documenting the success of projects such as Fold.it and Eyewire in high impact journals have raised wide interest in new applications of the distributed human intelligence that these systems have tapped into. However, the path from a good idea to a successful citizen science game remains highly challenging. Apart from the scientific difficulties of identifying suitable problems and appropriate human-powered solutions, the games still need to be created, need to be fun, and need to reach a large audience that remain engaged for the long-term. Here, we describe Science Game Lab (SGL) (https://sciencegamelab.org), a platform for bootstrapping the production, facilitating the publication, and boosting both the fun and the value of the user experience for scientific games with a purpose.
Introduction
Ever since the Fold.it project famously demonstrated that teams of human game players could often outperform supercomputers at the challenging problem of 3d protein structure prediction, so-called ‘games with a purpose’ have seen increasing attention from the biomedical research community. A few other games in this genre include: Phylo for multiple sequence alignment, EteRNA for RNA structure design, Eyewire for mapping neural connectivity, The Cure for breast cancer prognosis prediction, Dizeez for gene annotation, and MalariaSpot for image analysis. Apart from tapping into human intelligence at scale, these efforts have also produced valuable educational opportunities. Many of these games are now used to introduce their underlying concepts in classroom settings where games in all forms are increasingly working their way into curriculums. Concomitant with the rise of these ‘serious games’, citizen science efforts such as the Zooniverse and Mark2Cure have sought similar aims but have packaged their work as volunteer tasks, analogous to unpaid crowdsourcing tasks, rather than as elements of games.
Many of these initiatives have succeeded in independently addressing challenging technical problems through human computation, improving science education, and generally raising scientific awareness. However, with so much interest from the scientific community and a booming ecosystem of game developers, there are actually relatively few of these games in operation now. Recognizing the opportunity, various groups have attempted to push the area forward through new funding opportunities and through various ‘game jams’ such as the one that produced the game ‘genes in space’ for use in analyzing microarray data in cancer. Here, we take a different approach towards expanding the ecosystem of games with a scientific purpose. Rather than attempting to seed the genesis of specific new game-changing games, we hope to lower the barrier to entry for new games and related citizen science tasks to generally promote the development of the entire field. With this high-level aim in mind, we developed Science Game Lab (SGL) to make it easier for developers to create successful scientific games or game-like learning and volunteer experiences. Specifically, SGL is intended to address the challenges of recruiting players and volunteers, keeping them engaged for the long term, and reducing the development costs associated with creating a scientific gaming experience.
The Science Game Lab Web application
SGL is a unique, open-source portal supporting the integration of games and volunteer experiences meant to advance science and science education (https://sciencegamelab.org). Unlike other related sites that act more like volunteer management and/or project directory services, such as SciStarter and Science Game Center, SGL is not simply a listing of related websites. Rather, it is an attempt to create a user experience that takes place directly within the SGL context yet still incorporates content from third parties. The system is largely inspired by game industry portals such as Kongregate that enable developers to incorporate their games directly into a unified metagame experience .
Players can use the portal to find and play games with their achievements within the games tracked on site-wide high score lists and achievement boards (Figure 1). Players can earn the SGL points that drive these leaderboards for actions taken in different games. In this way, SGL provides developers with access to a metagame that can be used to encourage players in addition to the incentives offered within individual games (Figure 2). This metagame can also be used by the system administrators to help direct the player community’s attention to particular games or particular tasks within games. For example, actions taken on new games might earn more points than actions taken on more established games as a way to ‘spread the wealth’ generated by successful games.
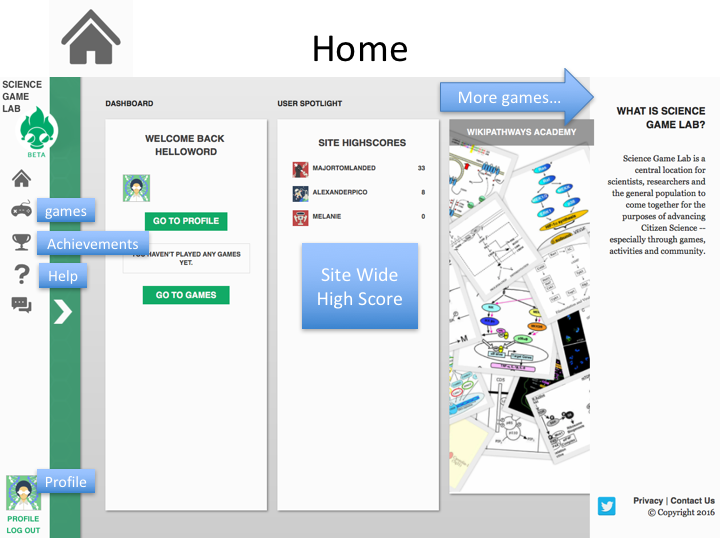 |
| Figure 1. SGL home page demonstrating site-wide high score list, game listing, and links to achievements, help, and user profile information. |
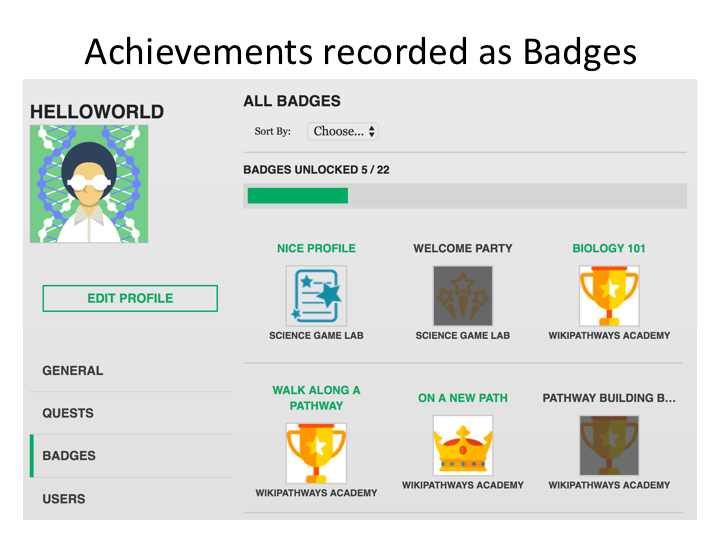 |
| Figure 2. Badges displayed on user’s profile page. Available badges not yet achieved are greyed out. |
Developers interact with SGL by incorporating a small javascript library into their application and using the SGL ‘developer dashboard’ to pair up events in their game with points, badges and quests managed by the SGL server. At this time, SGL only supports games that operate online as Web applications. The games are hosted by the developers and rendered in the SGL context within an iframe. The SGL iframe provides a ‘heads up display’ that provides real time feedback to game players with respect to events sent back to the SGL server such as earning points, gathering badges, or progressing through the stages of a quest (Figure 3). This display provides developers with the ability to add game mechanics to sites that are not overtly games. For example, Wikipathways incorporated a pathway editing tutorial into SGL, using the heads up display to reward users with SGL points and badges for completing various stages of the tutorial. The tutorial also took advantage of the SGL quest-building tool (Figure 4). Games are submitted by developers for approval by SGL administrators. Once approved, the games appear in the public view and can be accessed by any player.
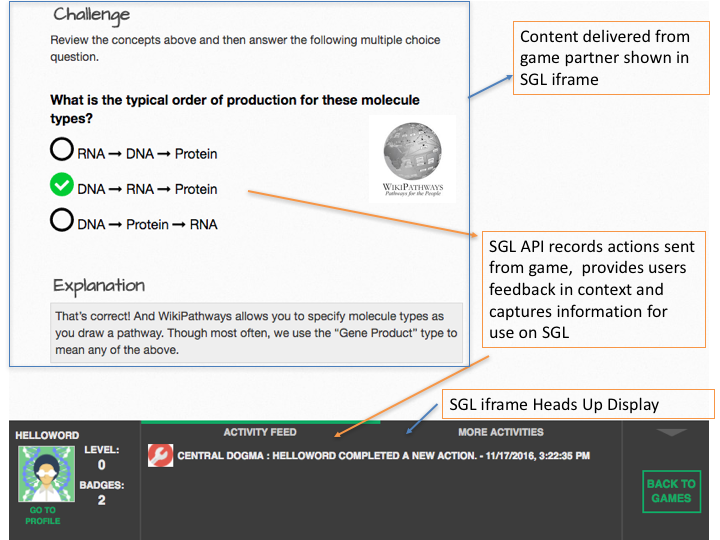 |
| Figure 3. The heads up display provided by the SGL iframe. Shows events captured by the API and provides users with immediate feedback. |
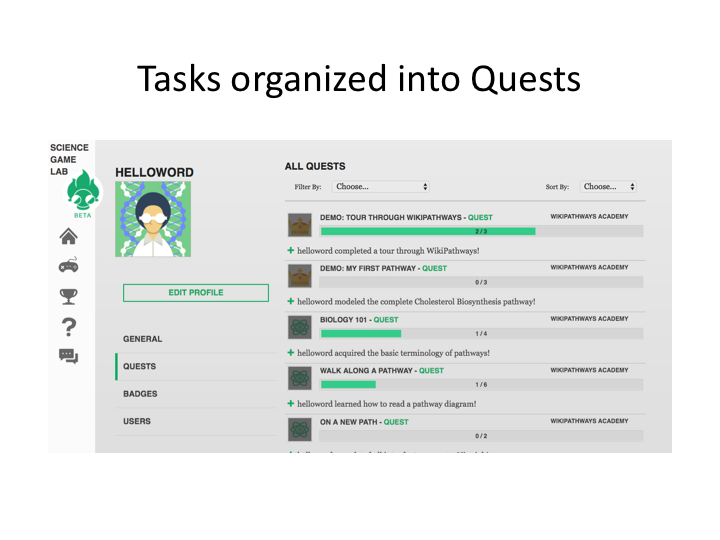 |
| Figure 4. Tasks in SGL can be grouped into quests. The figure shows a particular user’s progress through various quests available within the system. |
Discussion
If a critical initial mass of effective games can be integrated, SGL could strongly benefit new developers by providing immediate access to a large player population. Site-level status, identity and community features can help with the even greater challenge of long-term player engagement, a noted problem in the field. Within the context of science-related gaming, such status icons might eventually be used as practically useful, real-world marks of achievement inline with the notion of ‘Open Badges’. As demonstrated by the Wikipathways tutorial application, SGL can be used to replace the need for developers to host their own login systems, user tracking databases, and reward systems - all of which can be accomplished using the SGL developer tools. Citizen scientists are not homogenous in their motivations. Designing to be inclusive of gamers and non-gamers can be challenging. By offering an alternative means of experiencing a web-based citizen science application, SGL allows developers to cater to both their gaming and non-gaming contributor audience. Together, these features unite to raise the overall potential for growth within the world of citizen science and scientific gaming.
Future directions
SGL is currently functional, but so far has attracted only a small number of developers willing to integrate their content into the portal. Future work would need to address the challenge of raising the perceived value of integration with the site while lowering the perceived difficulty. Looking forward, key challenges for the future of SGL include better support for:
- games meant for mobile devices
- development of quests that span multiple games
- teachers to build SGL-focused lesson plans and track student progress
- creating new ‘SGL-native’ games
- integration with external authentication systems
None of these are insurmountable challenges, but they all require significant continued investment in software development. As an open source project, we encourage contributions from anyone that shares in our vision of spreading and doing science through the grand unifying principle of fun.






{kind=link}